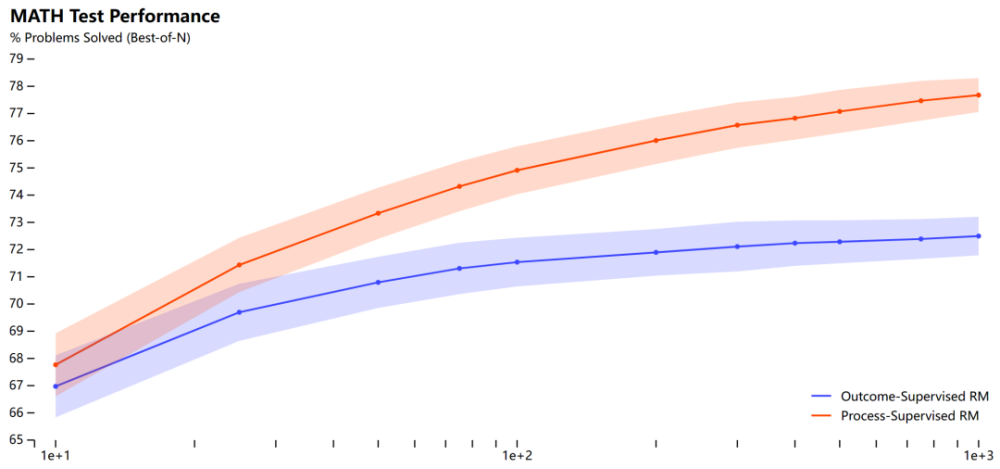
OpenAI要为GPT-4解决数学问题了:奖励模型指错,解题水平达到新高度

说起中央电视的主持人,很多人第一个想到的就是董卿了吧。今天小编就来盘点下董卿的6任风流情史。
关心男人工作辛苦暖心的句子?你需要个拥抱或者肩膀,我都在。我的超人,你要是累了,完全可以什么都不用管,一切有我。你放松一下也没有关系,我会在你休息的时候为你保驾...
日语文案温柔超仙短句?1.世界欠你的温容我来给。2.请你当我手心里的宝。3.书一笔清远,盈一怀暖阳。4.没有遗憾,给你再多幸福也不会体会快乐。5.要学会糊涂,别...
曾经的春晚就像一个造星舞台,捧红了一波又一波的人。作为一档全世界都在关注的节目,很多明星都把上春晚,当做自己的人生目标。靠着春晚,很多人的事业都发生了天翻地覆的变化,从默默无闻一举名扬天下,至今还在蒸蒸日上。
摩托车文案短句高级感?①1.上坡如存钱,下坡如花钱上坡有多累,下坡有多爽。 2.一个人骑车可以骑得更快,一群人骑车可以骑得更远! 3.骑行不在乎目的地,在乎沿途...…
近日,室温超导概念在股市比较火爆,很多投资者也开始关注相关的室温超导概念股票,那么室温超导概念股票有哪些呢?
寸止挑战,是指p站里的一个视频引发的挑战,男生按照视频的节奏进行自我安慰。
rap diss语录?怼人的押韵句子rap如下:一、脑子是个日用品,希望你不要把它当成装饰品。二、我给你的东西你得珍惜,特别是脸。三、你瞪我的样子,跟我家狗讨食...
最暖心的韩语情话短句有哪些?①나 를 용 서해 무표정 하 게 지 켜 보 는 사랑 너 가 깊다. 原谅我面无表情 却爱你很深②사랑해, 너랑 있음, 내맘이...
win10截图快捷键win+shift+s没有反应怎么解决?
微信变成英文了,怎么改回中文. 把手机拿给别人用,却不小心把微信的语言文字变成英文了,那么要怎么改回原来的中文模式,如何把语言转换成中文,为此,本篇先容以下方法,但愿可以匡助到你。
作为安卓阵营的真旗舰产品,三星S23 ultra的实力自然无需笔者多言,不管是在屏幕显示、影像技术、性能水平、续航方面,都能算做安卓阵营的顶尖,也算是保住了三星安卓机皇的“荣光”。虽说它的价格并不美丽,国行动辄上万的价格,也不是每一个消费者都买得起的,但是S23 ultra依然成为了热销单品。
苹果今天凌晨正式发布了iOS16.5首个预览版,不少果粉感叹道才发布的iOS16.4,为何这么快发布iOS16.5呢?又有哪些优化呢?下面就给大家分享首批忠实果粉升级iOS16.5的体验感慨感染。
在传统的摄影圈中,都有这样一个共识,再好的手机拍照性能也赶不上相机。主要原因是手机需要控制厚度与重量,无法把最提高前辈的部件装进去。手机摄影,与单反无法对比这是事实,但近年来其拍照水平有了具大的提升。特别有了芯片与算法的加持,成像效果已经可以满足大多数使用场景。所以,很多朋友在购买手机时,会越来越重视影视功能。
并不是所有的用户都追求高性能的旗舰手机,也有很多用户选择2000元以内的手机,这些手机的性价比比较出色,拥有强大的续航能力和优秀的性能,甚至在某些方面并不比旗舰手机差,在这些高性价比手机当中有三款非常出色,它们的质量都很强,而且有兔兔安的出色数据作为背书,仍是有一定信服力的。在二零二二年九月份当中,兔兔安根据2000元以下的手机进行了排名,排名前三的分别是OPPO K9 Pro,一加Ace竞速版,Redmi Note11T Pro,接下来小编将详细的介绍这三款手机。
Win11任务栏怎么透明?
身高163厘米,体重45公斤,可以负载5公斤重物,奔跑速度达6公里每小时,能在盲视状态下通过障碍物……4月27日,北京人形机器人创新中心在京发布人形机器人母平台“天工”,突破性地实现了纯电驱动的全尺寸人形机器人的拟人奔跑。这是北京人形机器人创新中心成立后发布的首款产品。
天眼查App显示,近日,浙江天猫商业科技有限公司成立,法定代表人为刘洋,注册资本1000万人民币,经营范围含互联网销售、通讯设备销售、单用途商业预付卡代理销售、计算机软硬件及辅助设备零售、信息系统运行维护服务、供应链管理服务等。股东信息显示,该公司由浙江天猫技术有限公司全资持股。
下载打开软件、勾选同意《隐私政策》、输入手机号等信息……现如今,这些快速注册应用软件的流程,已成为多数人默认操作。软件通过《隐私政策》会获取哪些个人信息?这些信息是软件提供服务所必需的吗?
过去一年,生成式 AI 的发展可以说是如火如荼,AI 已成为当下最重要的时代趋势。而今年,AIGC 落地到应用则成为关键词。在这个过程中,作为我们最重要的生产工具、协作工具,AI PC,成了承载 AI 理想走向现实的排头兵。
由傅崐萁率领的中国国民党民意代表参访团昨晚(26日)抵达北京,今天上午到访北京经济技术开发区,并试乘体验智能网联巴士。他们希望能够把大陆发展人工智能的经验带回岛内,未来两岸在这一领域可以加强合作交流。
“我们希望机器人帮人类扫地、洗碗